Searchable elements
Users can include the following types of linguistic items in their queries:
the exact phrase
Searches for the exact sequence of
word nodes whose respective
@form attributes correspond exactly (i.e. including grave vs acute accents) to the user input, unless the option
ignore diacritics is selected (this option may also be activated
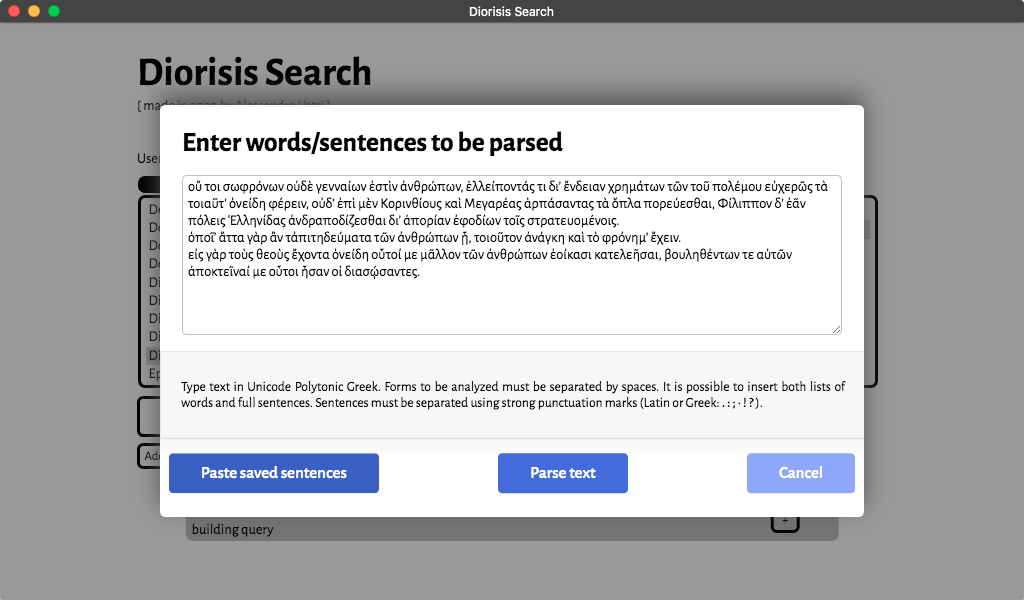
globally). Forms may be input either in Unicode (UTF-8) Polytonic Greek or in
BetaCode. Punctuation signs may not be included in the search and will be ignored by the search engine (e.g. the sequence λέγω ὅτι will return instances of both "λέγω ὅτι" and "λέγω, ὅτι").
the exact form
A
word whose form corresponds exactly (i.e. including the grave vs acute accents) to the user input, unless the option
ignore diacritics is selected (this option may also be activated
globally). Forms may be input either in Unicode (UTF-8) Polytonic Greek or in
BetaCode.
a form containing the sequence
A word node whose form contains the sequence (the string) input by the user.
For instance, πι selects all forms that contain πι (e.g.
πιστεύεις, Ἀσκλη
πιῷ, etc., but not ἐλπίζων or πίπτει, unless the option
ignore diacritics is selected). Strings may be input either in Unicode (UTF-8) Polytonic Greek or in
BetaCode.
a form of the lemma
A word whose lemma corresponds exactly to the one selected by the user from the list of lemmas
occurring in the Diorisis Corpus (and not all lemmas in e.g. LSJ, some of which would not be found anyway!). Lemmas may be input either in Unicode (UTF-8) Polytonic Greek or in
BetaCode with all diacritics (even if the option
ignoring diacritics is active).
a form of the lemma that contains the sequence
A wordwhose lemma contains the sequence (the string) input by the user.
For instance, πι selects all forms of lemmas that contain πι (e.g.
πιστεύω, ἐ
πιλαμβάνω, etc., but not ἐλπίς, unless the option
ignore diacritics is selected). Strings may be input either in Unicode (UTF-8) Polytonic Greek or in
BetaCode.
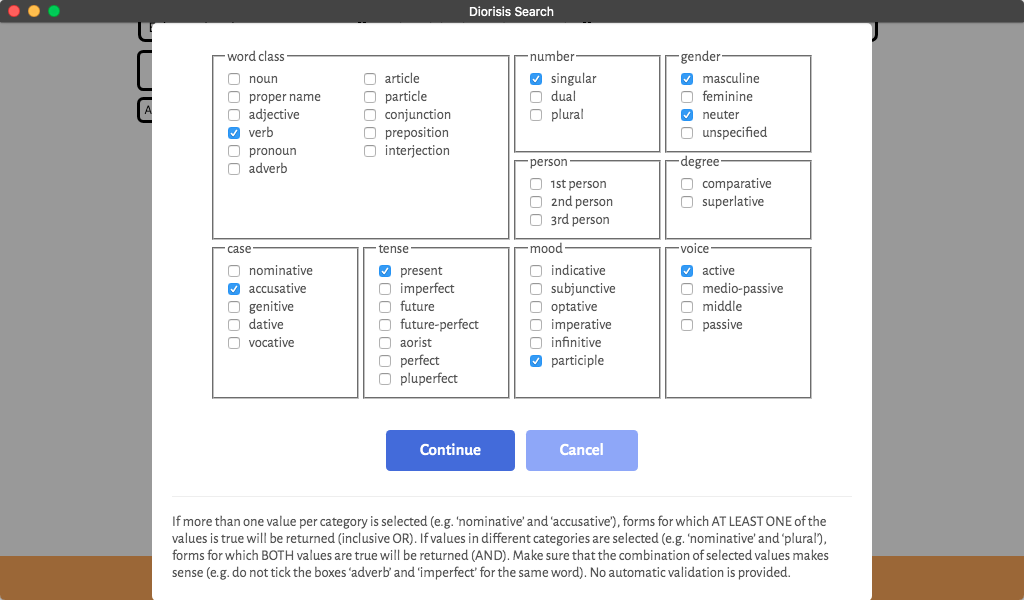
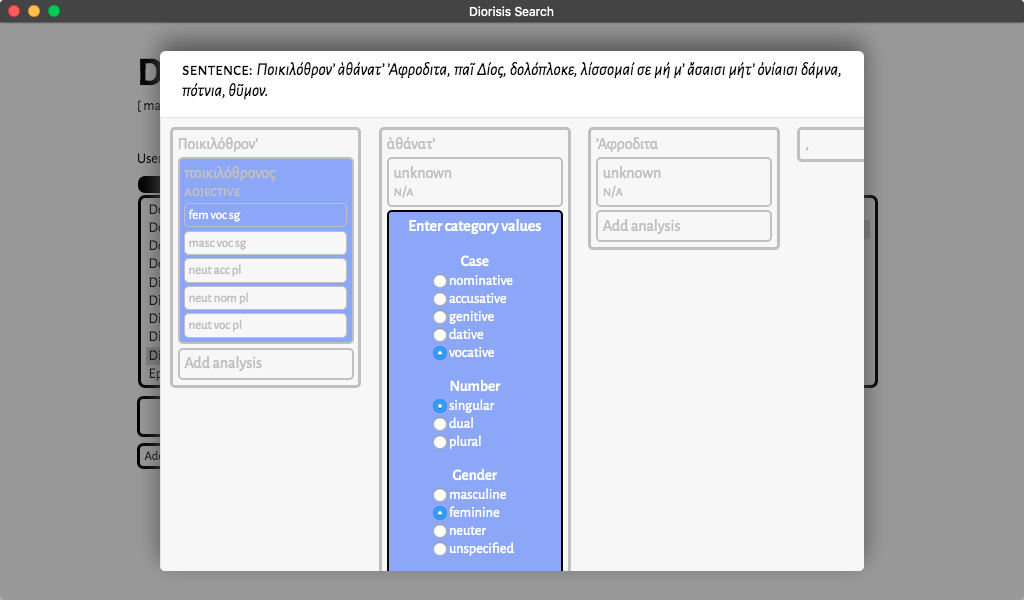
a word with the following morphological features
A word of which at least one possible morphological analysis corresponds to the combination of values input by the user.
the punctuation mark
A punctuation mark corresponding to the user input.
If words are selected according to their form or lemma, users have the option to specify which morphological analyses should be possible for the word, if required.
Search commands
The relationship between linguistic items in the linear order of the sentence can be specified in the following ways:
followed by
Requires that the first word or punctuation mark should be followed by a word or punctuation mark whose features the user will be prompted to specify.
If the first element in the query is a strong punctuation mark (full stop, middle dot, or question mark), the search will be extended to the immediately following sentence (e.g. queries can capture words that follow a question mark within the following sentence).
followed or preceded by
Requires that the first word or punctuation mark should be followed or preceded by a word or punctuation mark mark whose features the user will be prompted to specify.
This command is not available if the first element in the query is a strong punctuation mark (full stop, middle dot, or question mark).
followed by (ignore punctuation)
Requires that the first word or punctuation mark should be followed by a word mark whose features the user will be prompted to specify.
If the first element in the query is a strong punctuation mark (full stop, middle dot, or question mark), the search will be extended to the immediately following sentence (e.g. queries can capture words that follow a question mark within the following sentence).
NB: The scope of the search is defined by counting only the number of word nodes.
For instance, in the sequence [ ὦ ἄνδρες, ἐγὼ ], ἐγὼ counts as immediately following ἄνδρες (scope = 1).
If used to include in the query more than one element after the first, this command will appear as preceded by the word and in the drop-down menu.
followed or preceded by (ignore punctuation)
Requires that the first word or punctuation mark should be followed or preceded by a word whose features the user will be prompted to specify.
NB: The scope of the search is defined by counting only the number of word nodes.
For instance, in the sequence [ ὦ ἄνδρες, ἐγὼ ], ἐγὼ counts as immediately following ἄνδρες (scope = 1).
When any of these commands is selected, the user will also be prompted to indicate the scope of the search (i.e. the required distance or range of distances of the target from the first element).
or
Specifies that the first element may be defined by an alternative set of features. This command is only available while specifying the first element of the search.
ignoring diacritics
Requests that all diacritics signs be ignored in all form- and lemma-based searches. This option may be activated selectively for individual elements.
All elements may be searched for negatively, that is, it is possible to search for elements that match any feature but those specified (e.g. anything but the exact form instead of the exact form).
The maximum scope of a search is one sentence. In the Diorisis Corpus, sentences are defined as sequences of words and punctuation marks delimited by a strong punctuation mark (full stop, middle dot, or question mark).
Within the sentence, searches for individual
elements to follow or precede the first one may be restricted to a specific range (
scope) for each
element. The following options are available:
within
The search engine will search for the specified element within one and the specified number of elements from the first element.
For instance, a search for the form ἀνὴρ within 3 words after the form ὁ will capture sequences like ὁ ἀνὴρ, ὁ δ’ ἀνὴρ, ὁ αὐτὸς ἀνὴρ, or ὁ δ’ αὐτὸς ἀνὴρ.
With the commands followed by or followed or preceded by, the range is calculated counting the number of word and punct nodes.
between
The search engine will search for the specified element in elements at a distance from the first element ranging within the specified lower and upper end.
For instance, a search for the form ἀνὴρ between 2 and 3 words after the form ὁ will capture sequences like ὁ δ’ ἀνὴρ, ὁ αὐτὸς ἀνὴρ, or ὁ δ’ αὐτὸς ἀνὴρ, but not ὁ ἀνὴρ.
With the commands followed by or followed or preceded by, the range is calculated counting the number of word and punct nodes.
exactly
The search engine will search for the specified element in elements at the specified distance from the first element.
For instance, a search for the form ἀνὴρ exactly 2 words after the form ὁ will capture sequences like ὁ δ’ ἀνὴρ or ὁ αὐτὸς ἀνὴρ, but not ὁ ἀνὴρ or ὁ δ’ αὐτὸς ἀνὴρ.
With the commands followed by or followed or preceded by, the range is calculated counting the number of word and punct nodes.
With the commands followed by (ignore punctuation) or followed or preceded by (ignore punctuation), the range is calculated counting the number of word nodes only (and, as a consequence, it is wider).
in the same sentence
The search engine will search for the specified element in elements in the same sentence as the first element.
Results
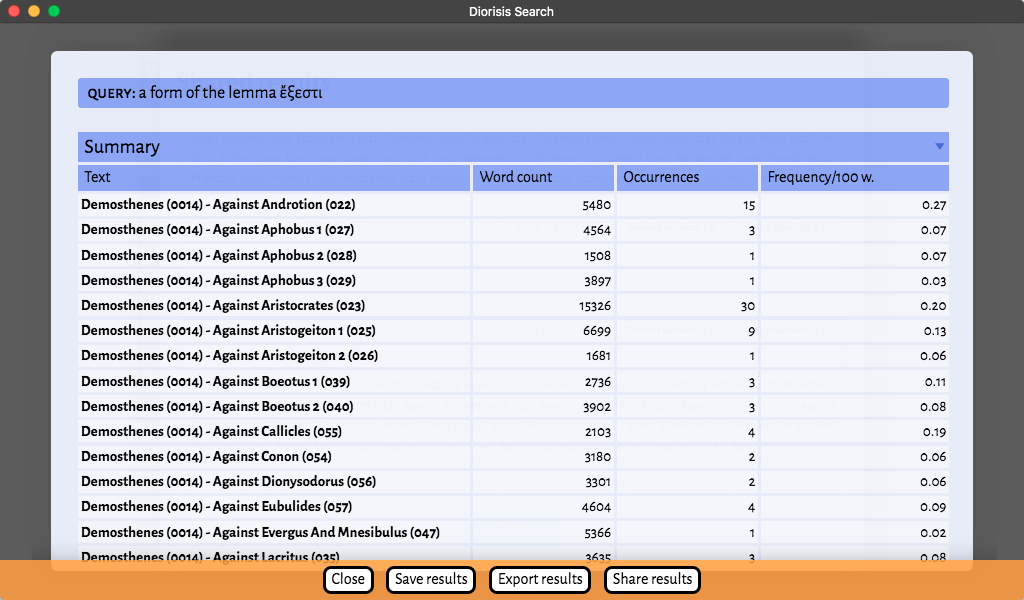
Diorisis Search returns the following data:
- Summary: a table showing the number of
word tokens in each document, the raw count of the occurrences of the search pattern, and its relative frequency per 100 word in each document.
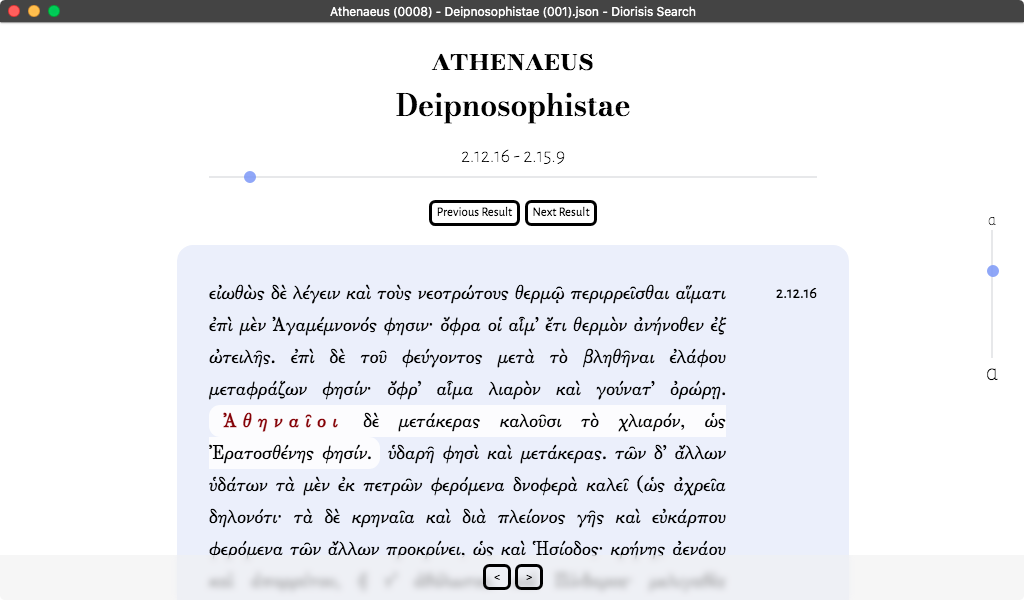
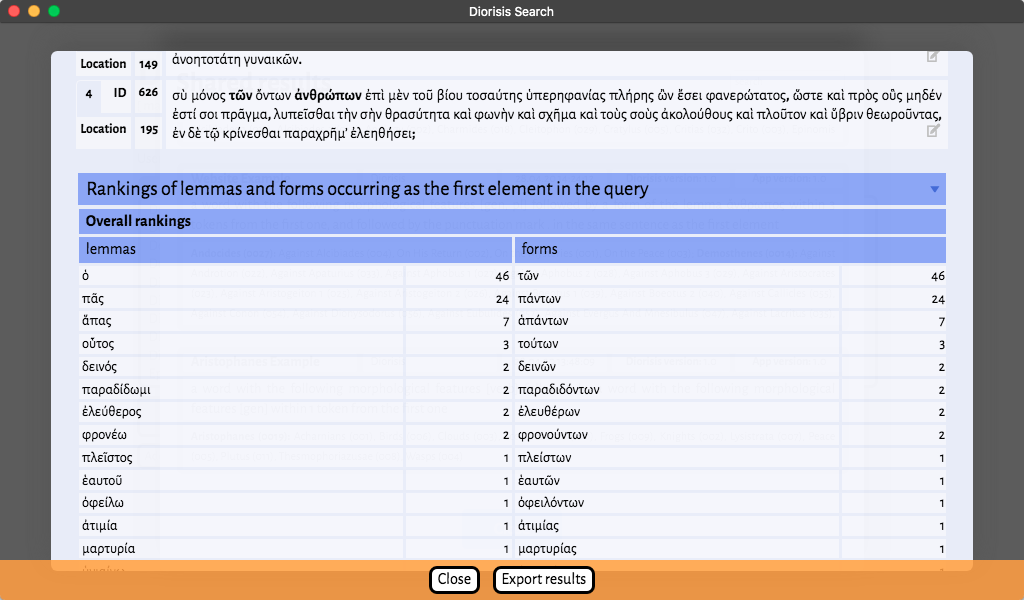
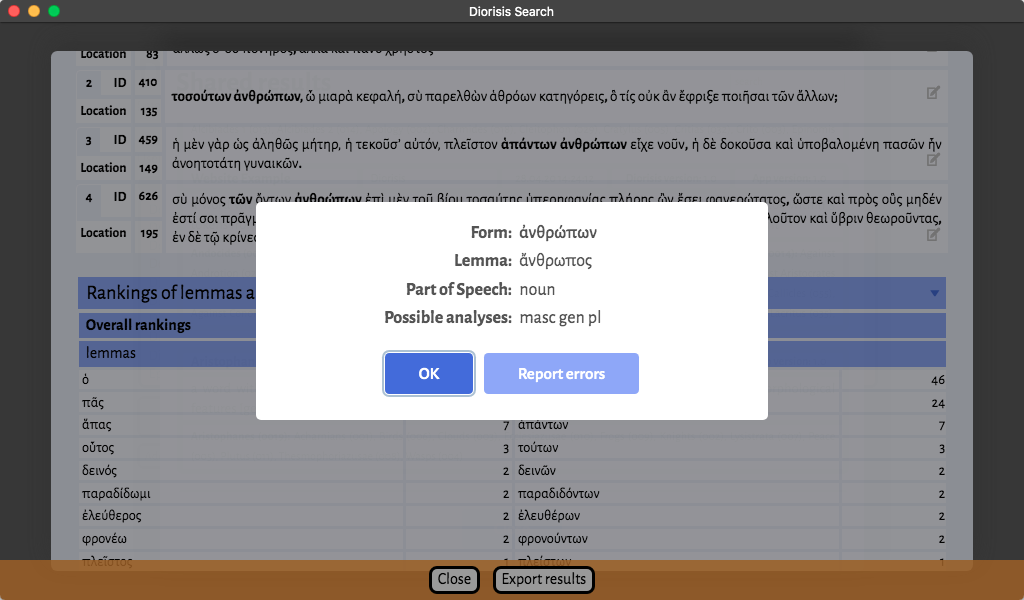
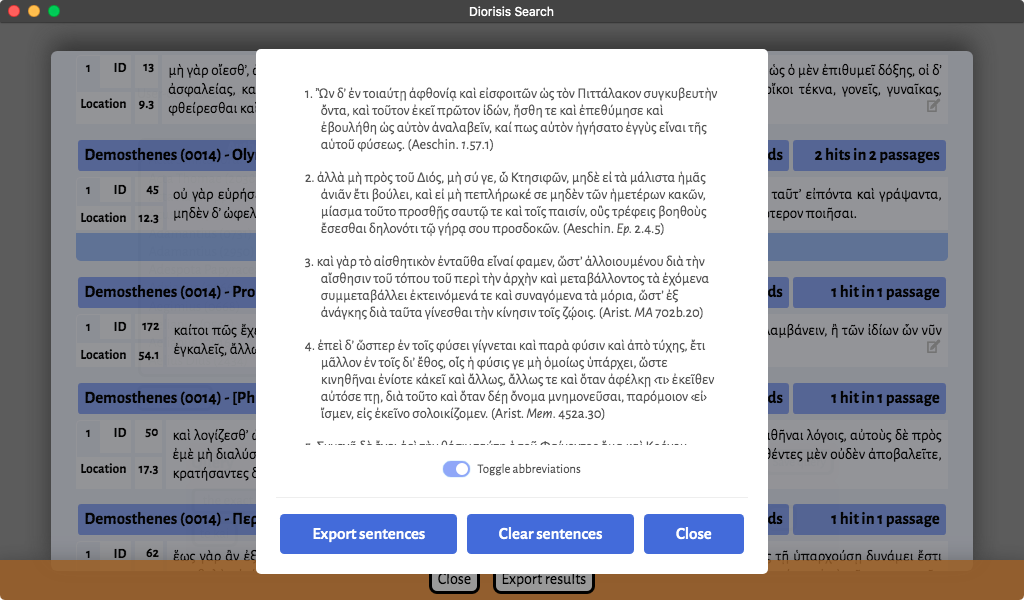
- Result Sentences: all the sentences in which occurrences of the searched pattern are found. Results are grouped by text, and the elements captured by the query are highlighted in bold. All words in each sentence are clickable. Clicking on a word opens a pop up displaying its lemma and possible morphological analyses.
- Rankings of lemmas and forms occurring as the first element in the query: the raw count of lemma and forms occurring as the first element in the query (ranked from high to low count, listing up to 100 elements). If one wishes, for instance, to discover which verbs directly precede a genitive in Aristophanes, this is the data to look at.
The main table contains the aggregate data for all the texts searched and is followed by a table per text (if only one text is included in the corpus, the data will coincide).
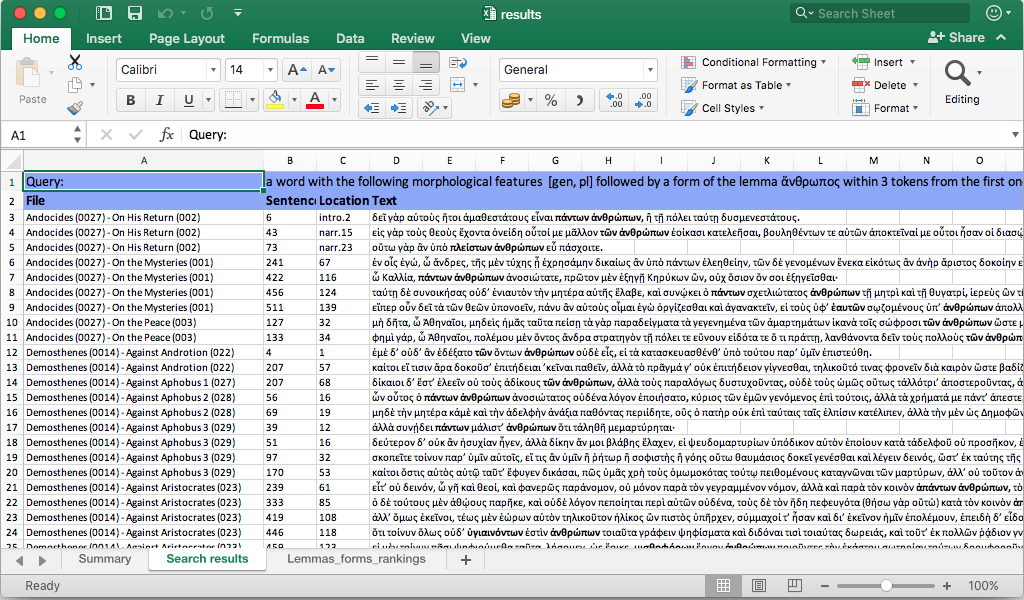
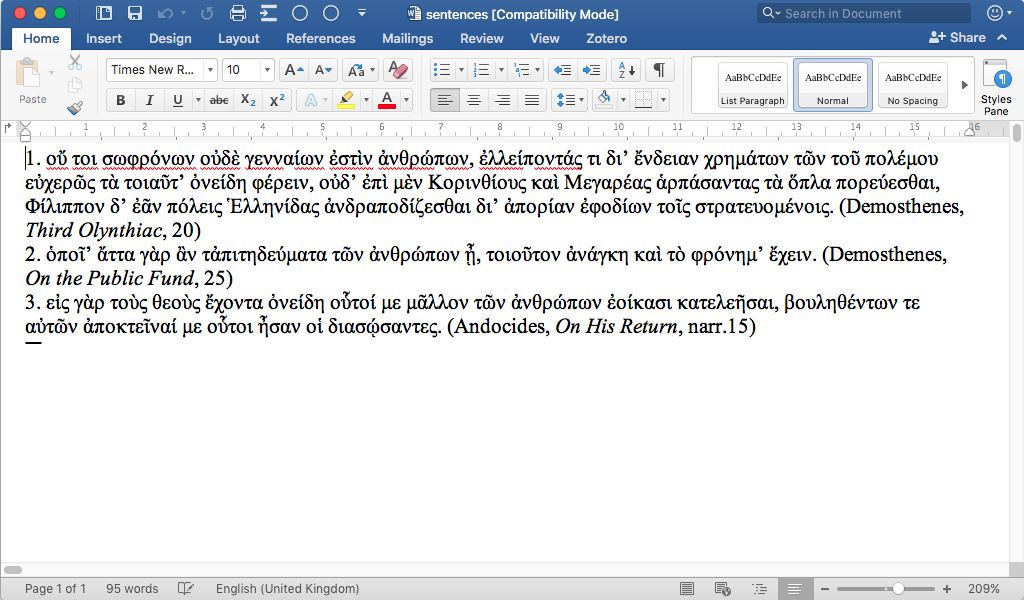
Result sentences can be saved in the Saved Sentences workbook. Saved sentences are temporarily stored in memory, along with their exact reference, and may be viewed and as a Microsoft Word 2010+ docx document for use e.g. in handouts, exercises, or other teaching materials.